
DB2 V4.1 introduces a new type of index. The new index type is called Type 2. The old index type is, as one might expect, now called Type 1. Many of the valuable V4.1 enhancements depend on the use of Type 2 indexes.
| Row-level locking. (Row-level locking is not permitted if Type 1 indexes are used.) |
| No locking in the index. (In a Type 1 index, locks are acquired on index pages and subpages. Type 2 indexes require no locks on their pages.) |
| Index access with Uncommitted Read (UR) isolation. (UR is not valid for access via a Type 1 Index. It is, however, valid for access without an index.) |
| Query parallelism with index access. |
| Concurrent utility (e.g. LOAD) access to separate logical partitions of a partitioned tablespace having a Type 2 secondary index. (Not possible if the secondary index on the partitioned tablespace is a Type 1 index.) |
| Ordered RID chains for non-unique indexes. (A performance improvement over Type 1 indexes, which do not maintain the RIDS in any particular order.) |
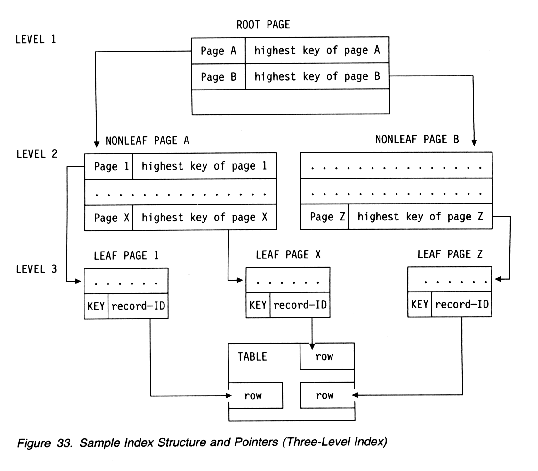
For those who want to know more, the following prose and diagram are lifted from pages 2-57 through 2-58 of the DB2 Version 4 Administration Guide:
Type 2 indexes differ from type 1 indexes in that:
- Type 2 indexes have no subpages.
- Type 2 indexes require no locks on their pages. A lock on the data page or row locks the index key.
Type 2 indexes support high concurrency by locking the underlying data page or record. Only one lock is held after an update to a data row or page and its associated indexes.
(In some cases, this might produce contention that does not occur with a type 1 index. For example, a type 2 index scan might require locks on data pages, but a type 1 index scan does not. Hence, the index scan might contend with an update operation.)- With type 2 indexes, no locks are acquired on index pages during modifications of index structures. A structure modification (such as page splits or page deletions) is an index operation that updates the nonleaf portion of the index tree and changes the structure of the tree. Other transactions can read or modify pages involved in structure modifications.
- Type 2 indexes use suffix truncation on nonleaf pages to store the high key values. Only enough of the prefix portion of the key is stored to distinguish it from the previous key. For example, suppose that during a leaf page split, the first key value on the new page is WXYZ4792 and the last key value on the previous page is WXW5341. Without suffix truncation, WXYZ4792 would be stored as the new high key value in the nonleaf page. With suffix truncation, only WXYZ is stored as the new high key value. Depending on the nature of the index key (if most of the keys are alike) there could be a reduction in the number of index levels and, consequently, in the number of pages read and in the cost of I/O for index access.
- The record identifiers (RIDs) stored with a type 2 nonunique index entry are kept in ascending order.
This RID ordering is maintained so that a binary search can locate the RID of interest efficiently. RID maps for type 2 indexes can contain as many RIDs as will physically fit on the page; they are not limited to 256 entries, as in type 1. Deleting a single duplicate no longer requires a slow sequential search of duplicates that can span multiple leaf pages. RID ordering improves performance in deleting or updating entries, when the number of duplicates is in the thousands.- Unless the table or table space is locked in mode X, a DELETE operation does not physically remove the entry. Instead, it pseudo-deletes the entry by leaving it in the page, but marks it for deletion. The space remains available in the index at least until the data is committed, so if a rollback takes place, there will always be enough room to insert the deleted entry and avoid the need to split the page. After the deleting operation commits, the committed pseudo-entry can be physically deleted when space is needed for an insert, or when the percentage of pseudo-deleted entries marked on a page reaches a certain threshold.
- There are four types of index pages: the header page, space map page, leaf page and nonleaf page. With type 2 indexes, the formats of these pages change. For example, type 2 space maps cover fewer pages, but contain more information per page, than type 1 space maps.
- There are no one-level type 2 indexes. A type 2 index is created as a two-level index with a root page that points to an empty leaf page.
- With the new type of index, the predicate can be evaluated when the index is accessed, particularly if all columns in the predicate are in the index. If not all columns are present in the index, some evaluation might still be possible when the index is accessed, and then the predicate is evaluated further when the data is accessed.



©Copyright 1996 Chuck Anesi all rights reserved